Our AI series continues with what investors need to know about how large language models (LLMs) work to make informed AI investments.
How ChatGPT Works
To make intelligent investments, an investor should have an understanding of how a company’s product works. Even if it’s a technical product like AI. With scorching investor excitement around AI, we should all make sure we understand the basics of what we’re investing in.
Here are the basics on large-language models (LLMs) like ChatGPT that are driving the AI boom.
What is an LLM?
A large-language model is a neural network that is trained to infer what words should come next in a sequence based on some prompt.
As we’ve detailed before, LLMs don’t “understand” the meaning of text like a human does. Instead, LLMs understand a text through statistical interpretation by learning from vast amounts of data. When an LLM answers a user’s question, it’s making an intelligent guess about what words and sequences of words make sense to come next given the question and the existing sequence of the answer so far.
There are several AI-specific terms in our LLM definition: neural network, training, inference, and prompt. I’ll define each in a simplistic way.
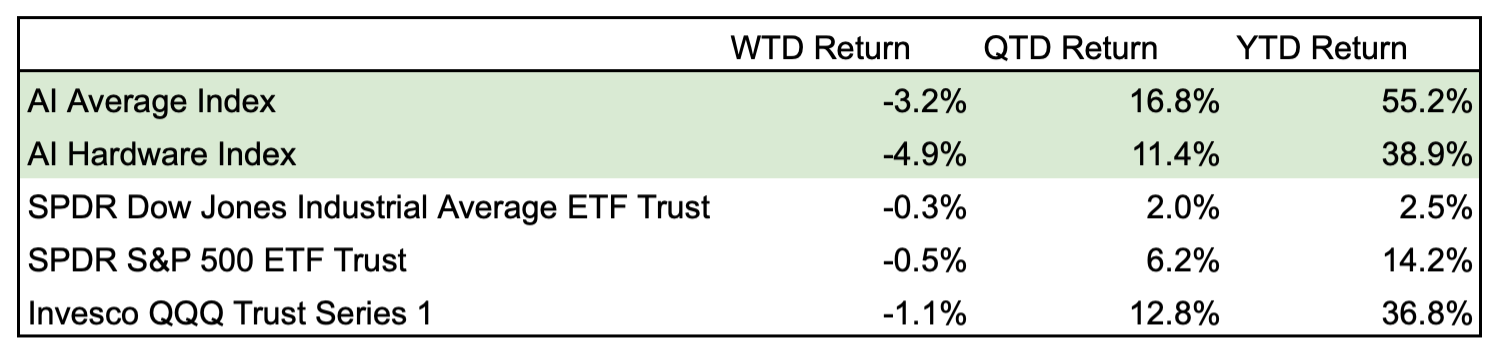
Neural Network
A neural network is a computer algorithm trained to recognize patterns. A neural network consists of many interconnected nodes — like neurons in the human brain — of varying weights and biases that determine the output of the model. The weights and biases in a neural network are known as parameters.
LLMs are often sized by the number of parameters in the model. More parameters suggest a more complex model. OpenAI’s GPT-4 reportedly has one trillion parameters vs 170 billion parameters in GPT-3. Google’s PaLM2 is trained on 340 billion parameters.
One of the reasons language-based AI seems further advanced than vision is the size of the models. The largest vision transformer model is Google’s recent ViT-22B with 22 billion parameters, one-fiftieth the number of parameters of GPT-4. Tesla’s neural network for autonomy had one billion parameters as of late 2022. Vision is a different function than language, and it may not require as many parameters to break through like GPT, but it seems logical to believe more parameters in vision would lead to better robots.
Sam Altman thinks parameter count in LLMs will continue to grow but that the use of parameters as a measure of model function is getting less useful. Humans love quantification. I suspect we’ll always have some measure of function to compare LLMs so long as we have multiple models to choose from. If we reach an AGI, measurement may no longer matter.

Training
Training is the process of teaching an LLM how it should answer queries by establishing the weights in the neural network. Most of today’s LLMs train in two core parts. First a model is pre-trained, which means it’s given a large dataset of text to form some basic understanding of patterns in language. Pre-training datasets often consist of trillions of words. After pretraining, the model is capable of generating some output, but that output is rough and machine-like. It’s not polished or conversational. Optimization happens in the second step through a supervised learning process that adjusts weights in the network to improve the model’s ability to respond. The most important optimization of modern LLMs is a process called reinforcement learning from human feedback (RLHF). In this step, humans tell the model how to improve output via ranking and rewriting of model responses.
Training is expensive. The training of GPT-4 cost over $100 million. Training expense comes in two parts. There’s the expense of compute for performing the many billions of calculations in the training process and the expense of human model optimization where there’s no way to scale effort. More human feedback is a linear function that requires more human hours. The more human feedback a model receives, the more human-like the model’s responses. This is why the data segment of my AI mental model (compute, data, interface) is the most underappreciated of the three categories. The preparation of data used in training ultimately determines the quality of the response and thus the end user experience.
Inference
Inference is when a model makes a prediction — it infers something based on its training and some user input.
The many differences between training and inference will help define investment opportunities around each function:
- Training is done infrequently — only when the model needs improvement. Inference is done as frequently as users interact with the AI.
- Training is one long iterative process vs inference as one short single process (although it may be followed up with additional user prompts).
- Training speed matters primarily as a function of cost. Inference speed matters primarily as a function of user experience. We don’t like waiting for Google search results, nor do we like waiting for ChatGPT responses.
- On the matter of waiting on ChatGPT responses, you can think of inference happening in many small bits. Every user interaction forces an inference. Some of these calculations can be batched to enhance system efficiency which is why I believe sometimes ChatGPT is slower to respond.
- Training will almost always happen in a centralized location, usually a cloud, where the model can serve many end points whether that be devices or user interfaces. Inference can happen in the cloud for something like ChatGPT, but it might also happen on the edge (locally on a device). Running inference on the edge makes sense for applications that work on sensitive data or where latency is an issue. Self-driving cars, for example, run inference on the edge because the system needs to make real-time decisions and latency or interruption in a signal to the cloud could cause an accident.
Prompt
By now, the definition of prompt may seem obvious. A prompt is the question or statement a user submits to a model for a response. It’s the AI version of a query in search. Prompts are also used in the training process where curated prompts are fed to the model then human feedback is given based on the model’s responses.
A lot of AI depends on the reuse of prompts to create various functions and enhance the usefulness of AI algorithms. One recent example is AI Agents like Auto-GPT or BabyAGI which are GPT-based tools that develop prompts for itself in service toward completing some task defined by a user like ordering a pizza or booking a flight. This will be a topic for a future post.
Applying My AI Mental Model to Companies
Our definition of an LLM — a neural network that is trained to infer what words should come next in a sequence based on some prompt — fits into my mental model for investing in AI via the major categories of compute, data, and inference.
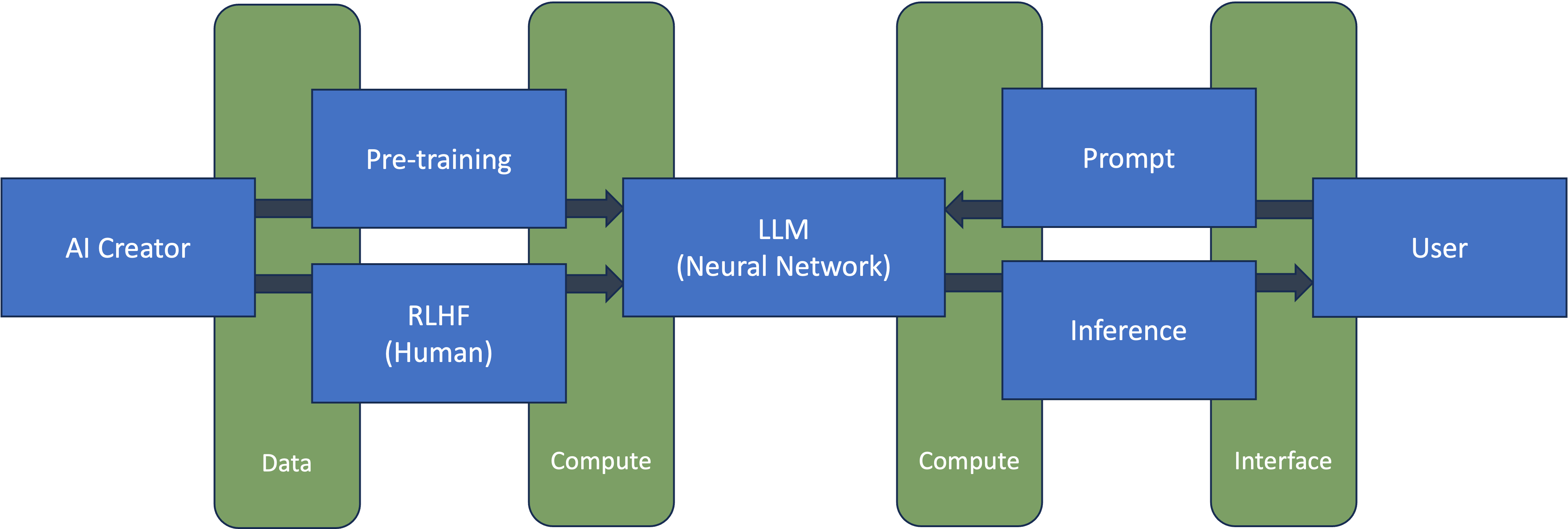
Data
We can think of the process starting from left to right. The creation of an AI system starts with training on some dataset. Thus every company that creates an AI algorithm is a data company first. Per my mental model, the way you win in data businesses is to improve accessibility and usability of data, primarily through dealing with unique data.
Compelling AI creators engage in collecting proprietary datasets, optimizing them for pre-training a model, and refining the model through RLHF. All those activities create uniqueness that results in models that function better than others in specific domains. OpenAI has succeeded in creating data uniqueness through all of those tactics.
But not every AI data company creates algorithms. Some provide products and services to AI creators which are still a largely untapped opportunity for investing in AI.
In many cases, AI creators start with open source models that they may get from a company like HuggingFace. AI creators also outsource many parts of the training function, particularly RLHF. Companies like Invisible (a portfolio company of Deepwater) and ScaleAI help AI creators with RLHF. There are also specialized managed service companies like Pinecone that provide vector databases optimized for AI applications. For a few public examples, PLTR provides enterprises with data tools to create secure LLMs and other AI tools, while ESTC and MDB also play in the AI data management space.
As the AI space evolves, expect to see more products and services that assist AI creators in enhancing the usefulness of datasets to make more valuable models.
Compute
Compute sits between an AI creator and the end user handling training on the backend and inference on the front. Without compute, a model can’t’ be trained nor can it run inference. This is why we’ve seen rapid increases in infrastructure investment by large AI creation companies. Those providers need to build the scale to handle AI operations in the face of potentially rapid customer adoption. ChatGPT is close to one billion monthly active users only a little over six months post launch, making it the fastest growing website ever.
Obviously, NVDA has been the biggest beneficiary of the AI compute boom. NVDA provides the current state-of-the-art GPUs for handling both training and inference with 80-90%+ market share in AI workloads.
Many aim to challenge NVDA’s dominance, and the only way any chipmaker is likely to succeed in that challenge is to drive order of magnitude cost improvements.
AMD is the most obvious challenger to NVDA, having also played in the GPU space for decades. Last week, AMD announced its latest AI chip, the MI300X. One of the features of the AMD chip is that it supports a larger memory at 192GB than NVDA’s H100 chip at 120GB. But this is an incremental improvement that NVDA will ultimately match and surpass. The hard part for AMD is going to be creating the order of magnitude change in cost improvements while living in the same architecture and design constraints as NVDA.
To truly challenge NVDA, some chipmaker will need to experiment with alternative architectures and designs that create the possibility for 10x+ improvements on cost that are significant enough to move AI creators off of NVDA’s platform with which most are deeply tied to. Doing compute-in-memory is one such potential alternative.
While AMD may be able to take some small share with their new product, and that may be enough for the stock to work in the long run, it seems a poor bet that incrementalism will result in massive change in the compute space.
Interface
Interface companies win through distribution and scale.
We can think of interface companies in three flavors:
- End-to-end
- Light custom
- Front-end only
End-to-end AI creators are both data companies and interface companies that develop an integrated solution from algorithm to user experience. OpenAI with ChatGPT and DALL-E, Google with Bard, Anthropic with Claude. The aim of end-to-end development is to create a unique customer experience with the broadest distribution possible.
Light custom AI creators rely on third party algorithms (commercial or open source) that they customize with proprietary data for their own purposes to deliver a unique experience to end customers. RELX, owner of LexisNexis, uses GPT for its legal AI software. Khan Acadamy’s Khanmigo is ChatGPT trained on Khan Academy lessons. For many content and software companies with specific datasets, the light custom approach is the most efficient approach to bring an AI solution to customers. Expect many lightly customized chat solutions to emerge on just a handful of the most popular base LLMs.
Front-end only companies are a rarer breed that rely on tweaking elements of open source algorithms to function differently but don’t populate those algorithms with unique data. An example is the aforementioned Auto-GPT which turns GPT back onto itself to ask questions.
From an investment standpoint, the end-to-end space feels established. Odds are OpenAI, Google, and maybe a handful of other useful services emerge from that class. If one achieves general intelligence, it could be a winner-take-all space. The light custom space is probably most interesting but lends itself to extension of existing business/customer relationships rather than disruption of them. It seems most likely that the rush of enterprise and consumer companies to incorporate LLMs in product offerings will make it hard for upstarts to disrupt many existing digital businesses, although those that rely heavily on content may be more at risk than others.
Your Mental Model
AI stocks remain hot (see next section), and they’ll stay hot for the next several years as AI becomes more integrated into our everyday lives. AI algorithms may never understand things like a human, but hopefully you have a better human understanding of how these algorithms work and how to invest in them.
AI Index Update
I track the performance of two AI indices: the AI Average Index (AIAI) and AI Hardware Index (AIHI). The indices track a selection of relevant publicly traded AI companies to represent how investors are viewing the AI opportunity.
This past week, AI cooled down relative to the broader market, although much of that underperformance is centered on companies outside of the mega cap group. TSLA, AAPL, CRM, META, and NVDA were flat to up on the week. META was the top performer in the AIAI, while VRT was the top performer in the AIHI. VRT (Vertiv) makes cooling solutions for data centers.
Maybe this is some of the mean mean reversion I expected from last week. The volatility will remain as investors figure out the real impact of AI in the nearer term vs the longer term.